Shuffle流程————大数据分析学习笔记6
本文共 1221 字,大约阅读时间需要 4 分钟。

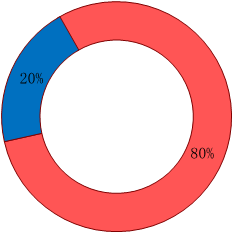 当达到阈值后,后台线程开始把内容溢出到磁盘(spill),每次达到阈值,都会新建一个spill file,map继续将数据写入环形缓冲区,如果缓冲区被写满,map会被阻塞 (2)写过程(spill)
当达到阈值后,后台线程开始把内容溢出到磁盘(spill),每次达到阈值,都会新建一个spill file,map继续将数据写入环形缓冲区,如果缓冲区被写满,map会被阻塞 (2)写过程(spill) 一,

二,
(3)首先要将Map端(可能有多个Map端)产生的输出文件拷贝到Reduce端。接下来就是sort阶段,即merge阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归并排序。最终在Reduce端生成一个较大的文件作为Reduce的输入。
面试怎么回答
map输出的数据到reduce之间一段过程,是mapreduce的核心
(1) 数据从map端出来,会首先进入环形缓冲区,环形缓冲区默认大小是100MB,默认阈值是80MB,在环形缓冲区中分区和排序,达到阈值新建一个spill文件,同时开始溢出和输入。 (2) 每10个流合并成一个spill文件 (3) 多个Spill文件合并成一个输出文件 (4) 如果环形缓冲区写满,map端会阻塞直到磁盘过程完成 (5) 多个map端的输出文件会被复制到reduce端进行归并排序并输出 注:【Combiner】就是一个简单Reducer操作,它在执行Map 任务的节点本身运行,先对Map 的输出做一次简单Reduce,使得Map的输出更紧凑,更少的数据会被写入磁盘和传送到Reducer转载地址:http://orqen.baihongyu.com/
你可能感兴趣的文章
USB通信记事
查看>>
Android 编译(1)——Android编译步骤梳理
查看>>
编译器配置(1)——ARMv7,ARMv8(AArch64) 浮点配置等相关知识
查看>>
Android 编译(2)——jack-server相关问题
查看>>
网络服务(2)——以太网配置IPV4和IPV6
查看>>
网络服务(3)——以太网phy的识别加载(RK3399)
查看>>
网络服务(5)——usb网卡名称修改(RK3399 Ubuntu)
查看>>
行业观察与理解-互联网巨幕下各行业的现状和发展
查看>>
数据结构与算法大全
查看>>
稳定排序和不稳定排序
查看>>
句柄泄露与CloseHandle()
查看>>
一些笔记
查看>>
SVN的安装和使用
查看>>
APP测试点分析
查看>>
JDK安装过程中出现“javac不是内部或外部命令”问题的解决
查看>>
Git使用教程
查看>>
APT使用指南
查看>>
adb介绍
查看>>
Android lint相关
查看>>
WebDriver介绍
查看>>